🏠 首页 / AWS / Cluster AutoScaler
Cluster AutoScaler #

我当前已经有了一个EKS服务搭建起来的K8s集群,我现在希望我的集群拥有自动伸缩(体现在节点的扩缩)的能力。
当我的集群资源充足,而我部署在集群中的应用只使用到了很少量的资源,我希望集群回收资源以节省费用;当我的应用服务越来越多,当前集群资源不足时,我希望集群能增加节点,以满足应用的部署条件。
那么本篇就是介绍如何通过使用Kubernetes Cluster Autoscaler让你的集群拥有自动伸缩的能力,而不用你时刻关注集群的资源是否过于宽松或紧张。
NodeGroup添加Tag #
我们创建EKS时,需要定义NodeGroup,一般在这个NodeGroup中定义:
asg_desired_capacity:期望创建的Node数量;
asg_max_size:最小Node数量,默认为1;
asg_min_size:最大Node数量。
定义的NodeGroup会生成Auto Scaling Group资源,并且由Auto Scaling Group来管理Node的创建。
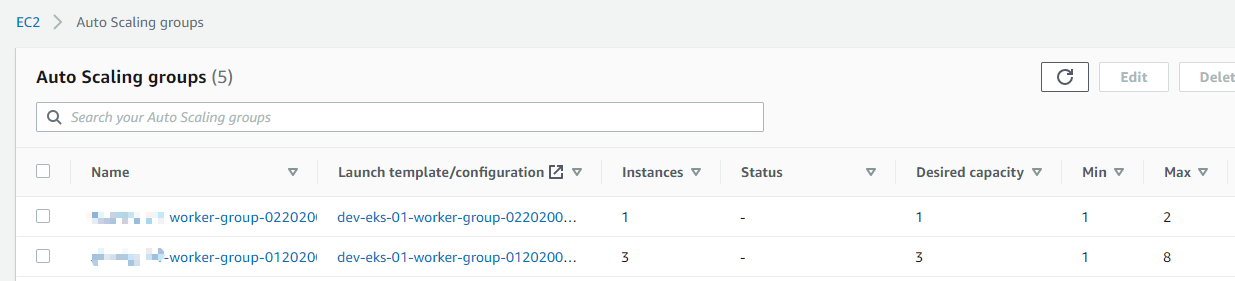
现在需要做的就是为你的Auto Scaling Group添加Tag。
tag键值:
| Tag Key | Tag Value |
|---|---|
| k8s.io/cluster-autoscaler/<your_cluster_name> | owned |
| k8s.io/cluster-autoscaler/enabled | true |
第一个Tag Key中的集群名<your_cluster_name>需要替换;
Tag Value的值是什么不重要,主要是需要这两个Tag Key来识别是否对这个集群开启Auto Scaling的能力。
添加Policy #
创建IAM策略,将新创建的策略Attach到集群节点绑定的IAM role上,让你的集群节点拥有自动伸缩的能力。
IAM策略Json内容:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeLaunchTemplateVersions"
],
"Resource": "*",
"Effect": "Allow"
}
]
}
部署Cluster AutoScaler #
在集群中部署Cluster AutoScaler,准备资源清单文件cluster-autoscaler.yaml:
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-addon: cluster-autoscaler.addons.k8s.io
k8s-app: cluster-autoscaler
name: cluster-autoscaler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cluster-autoscaler
labels:
k8s-addon: cluster-autoscaler.addons.k8s.io
k8s-app: cluster-autoscaler
rules:
- apiGroups: [""]
resources: ["events", "endpoints"]
verbs: ["create", "patch"]
- apiGroups: [""]
resources: ["pods/eviction"]
verbs: ["create"]
- apiGroups: [""]
resources: ["pods/status"]
verbs: ["update"]
- apiGroups: [""]
resources: ["endpoints"]
resourceNames: ["cluster-autoscaler"]
verbs: ["get", "update"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["watch", "list", "get", "update"]
- apiGroups: [""]
resources:
- "pods"
- "services"
- "replicationcontrollers"
- "persistentvolumeclaims"
- "persistentvolumes"
verbs: ["watch", "list", "get"]
- apiGroups: ["extensions"]
resources: ["replicasets", "daemonsets"]
verbs: ["watch", "list", "get"]
- apiGroups: ["policy"]
resources: ["poddisruptionbudgets"]
verbs: ["watch", "list"]
- apiGroups: ["apps"]
resources: ["statefulsets", "replicasets", "daemonsets"]
verbs: ["watch", "list", "get"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses", "csinodes"]
verbs: ["watch", "list", "get"]
- apiGroups: ["batch", "extensions"]
resources: ["jobs"]
verbs: ["get", "list", "watch", "patch"]
- apiGroups: ["coordination.k8s.io"]
resources: ["leases"]
verbs: ["create"]
- apiGroups: ["coordination.k8s.io"]
resourceNames: ["cluster-autoscaler"]
resources: ["leases"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: cluster-autoscaler
namespace: kube-system
labels:
k8s-addon: cluster-autoscaler.addons.k8s.io
k8s-app: cluster-autoscaler
rules:
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["create", "list", "watch"]
- apiGroups: [""]
resources: ["configmaps"]
resourceNames:
["cluster-autoscaler-status", "cluster-autoscaler-priority-expander"]
verbs: ["delete", "get", "update", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: cluster-autoscaler
labels:
k8s-addon: cluster-autoscaler.addons.k8s.io
k8s-app: cluster-autoscaler
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-autoscaler
subjects:
- kind: ServiceAccount
name: cluster-autoscaler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: cluster-autoscaler
namespace: kube-system
labels:
k8s-addon: cluster-autoscaler.addons.k8s.io
k8s-app: cluster-autoscaler
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: cluster-autoscaler
subjects:
- kind: ServiceAccount
name: cluster-autoscaler
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cluster-autoscaler
namespace: kube-system
labels:
app: cluster-autoscaler
spec:
replicas: 1
selector:
matchLabels:
app: cluster-autoscaler
template:
metadata:
labels:
app: cluster-autoscaler
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8085"
cluster-autoscaler.kubernetes.io/safe-to-evict: "false"
spec:
serviceAccountName: cluster-autoscaler
containers:
- image: us.gcr.io/k8s-artifacts-prod/autoscaling/cluster-autoscaler:v1.16.5
name: cluster-autoscaler
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 100m
memory: 300Mi
command:
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=aws
- --skip-nodes-with-local-storage=false
- --expander=least-waste
- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/<your_cluster_name>
- --balance-similar-node-groups
- --skip-nodes-with-system-pods=false
volumeMounts:
- name: ssl-certs
mountPath: /etc/ssl/certs/ca-certificates.crt
readOnly: true
imagePullPolicy: "Always"
volumes:
- name: ssl-certs
hostPath:
path: "/etc/ssl/certs/ca-bundle.crt"
资源清单内容比较长,但是需要注意的是 cluster-autoscaler 的 Deployment 资源中定义的 command 中,有一行你会觉得眼熟,没错就是我们上面为 Auto Scale Group 添加的 Tag,这里你也需要替换你的集群名 <your_cluster_name>,此外你可能需要替换使用到的镜像,你可以在
Cluster AutoScaler 发版页面去找对应的镜像版本。例如我的K8s集群是1.16,那么我需要找一个1.16.x版本的镜像。上面资源清单里就是使用了 us.gcr.io/k8s-artifacts-prod/autoscaling/cluster-autoscaler:v1.16.5 的镜像。
使用下面的命令创建 Cluster AutoScaler 资源:
kubectl apply -f cluster-autoscaler.yaml
查看Cluster AutoScaler #
我们部署完成之后,Cluster 默认每 10s 检查一次集群的资源情况,并根据资源情况判断是否需要扩缩容。
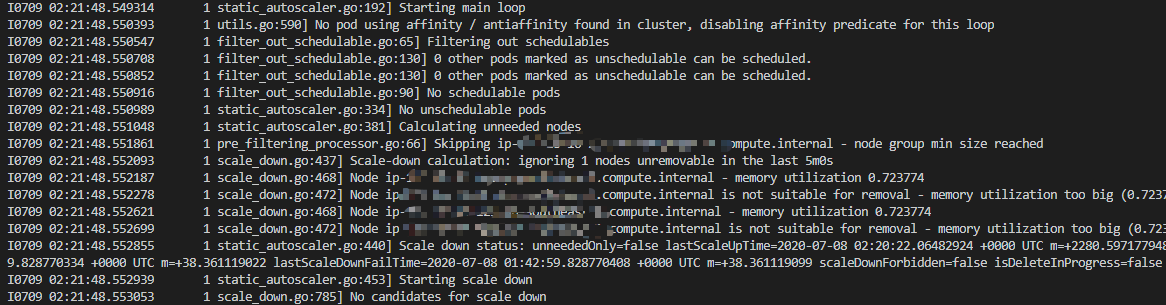
使用命令查看Cluster AutoScaler的检查情况:
kubectl logs -f deployment.apps/cluster-autoscaler -n kube-system
分析原理 #
你可以通过突然增加Pod示例数量,并且增加 Pod 的 resource.request.cpu/memory 设置为较高的值,这样来模拟集群资源紧张的场景,观察集群节点是否会自动扩容,之后将增加的 Pod 资源删除,再观察集群节点是否自动回收。这里我已经实践过了,由于演示起来比较复杂,可能会耗费很长的篇幅,所以这里就省去了,你可以亲自动手实践尝试。
相信有一个疑问一直环绕着,Cluster AutoScaler是怎么做到自动伸缩的呢,我们也没有给出类似于CPU超过75%就扩容的伸缩条件。我没有深入去研究,但是我自己根据Cluster AutoScaler的日志输出理解了一下。
Pod的申请的资源(resources.requests)与现有节点资源作比较,如果发现集群资源超出申请的资源能够使得我们移除一个节点的话,那么Cluster AutoScaler便会修改Auto Scaling Group的asg_desired_capacity值,例如-1,但是不会小于asg_max_size。当有新Pod部署,发现集群资源达不到新Pod申请的资源时,那么Cluster AutoScaler便会修改Auto Scaling Group的asg_desired_capacity值,例如+1,但是不会大于asg_max_size。只要修改了Auto Scaling Group的asg_desired_capacity值,那么集群节点便会自动伸缩。